Encoder, Decoder, Both: The Three Transformer Architectures

This is the third in a short series. The first (From Kernel Regression to Self-Attention) derived self-attention. The second (Masks and Cross-Attention) covered the two extensions every real Transformer uses — masks and cross-attention. This one zooms out one level: those mechanisms are building blocks, and BERT, GPT, and T5 are architectures built by stacking them in different ways.
If you have ever wondered why the original Transformer paper had both an “encoder” and a “decoder,” but BERT is called “encoder-only” and GPT is called “decoder-only” — this post is for you.
Historically, the encoder–decoder came first and the others were carved out of it. Conceptually, it is easier to go the other way: start with the simplest stack and add one mechanism at a time. So we will build up from BERT to GPT to the original Transformer.
1. Encoder-only: BERT and friends
The simplest Transformer architecture is a single stack of identical blocks, each containing self-attention and a feed-forward network. No mask, no cross-attention, no second stack.
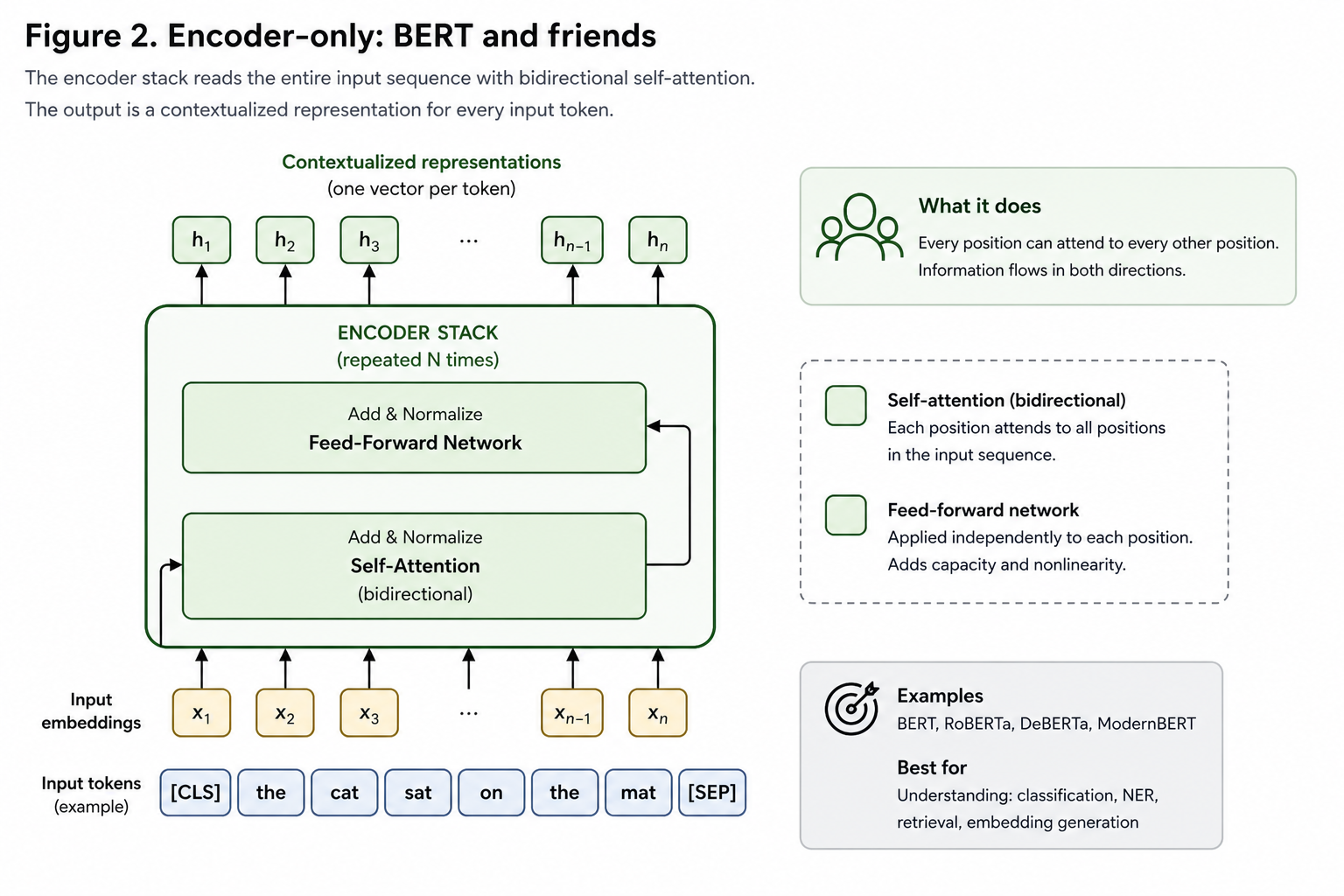
This is BERT (Devlin et al., 2018) and its successors — RoBERTa, DeBERTa, ModernBERT. Every position attends to every other position, in both directions. The output is a contextualized vector for each input token.
Bidirectional attention is exactly what you want for understanding — sentence classification, named entity recognition, embedding generation. Classifying a word benefits from seeing what comes after it as well as before. There is no generation here; the model produces representations, not tokens.
2. Decoder-only: GPT, Llama, Claude
Now add one mechanism: a causal mask on the self-attention layer.
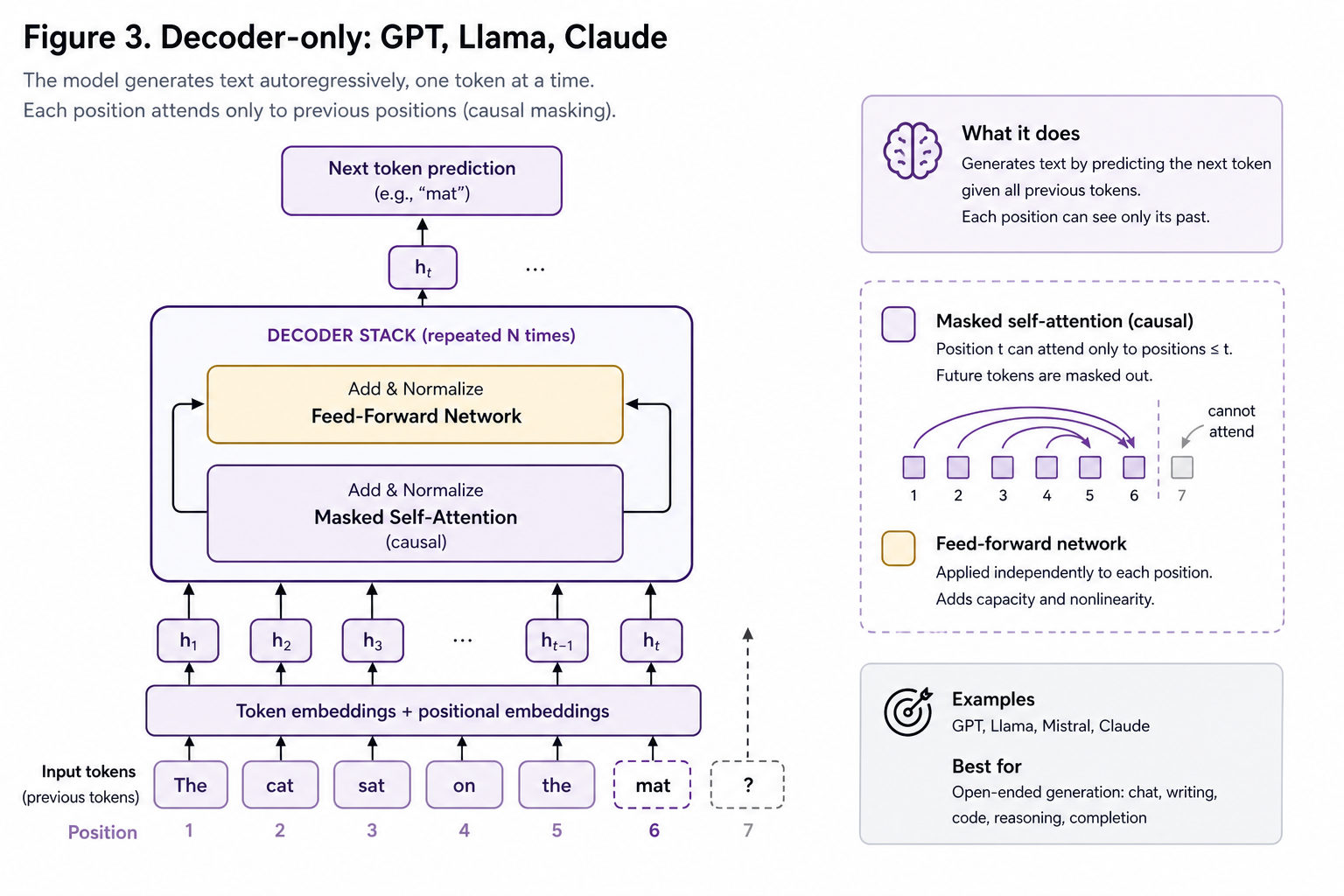
The architecture is otherwise identical to encoder-only: one stack of blocks, each with self-attention and a feed-forward network. The only difference is that each position can now attend only to itself and earlier positions — the future is hidden.
That single change unlocks open-ended generation. Because no position depends on future tokens, the model can be trained to predict the next token at every position in parallel, and at inference time it can emit one token at a time, feeding each output back as input. GPT, Llama, Mistral, and Claude are all built this way.
These models are called “decoder-only,” for reasons that will make more sense in the next section. The name is a bit of a historical accident.
3. Encoder–decoder: the original Transformer
The original Transformer (Vaswani et al., 2017) was built for machine translation, where you have a clearly distinct input (an English sentence) and output (its German translation). To handle that, it combines both of the stacks above and adds one more mechanism — cross-attention — to bridge them.
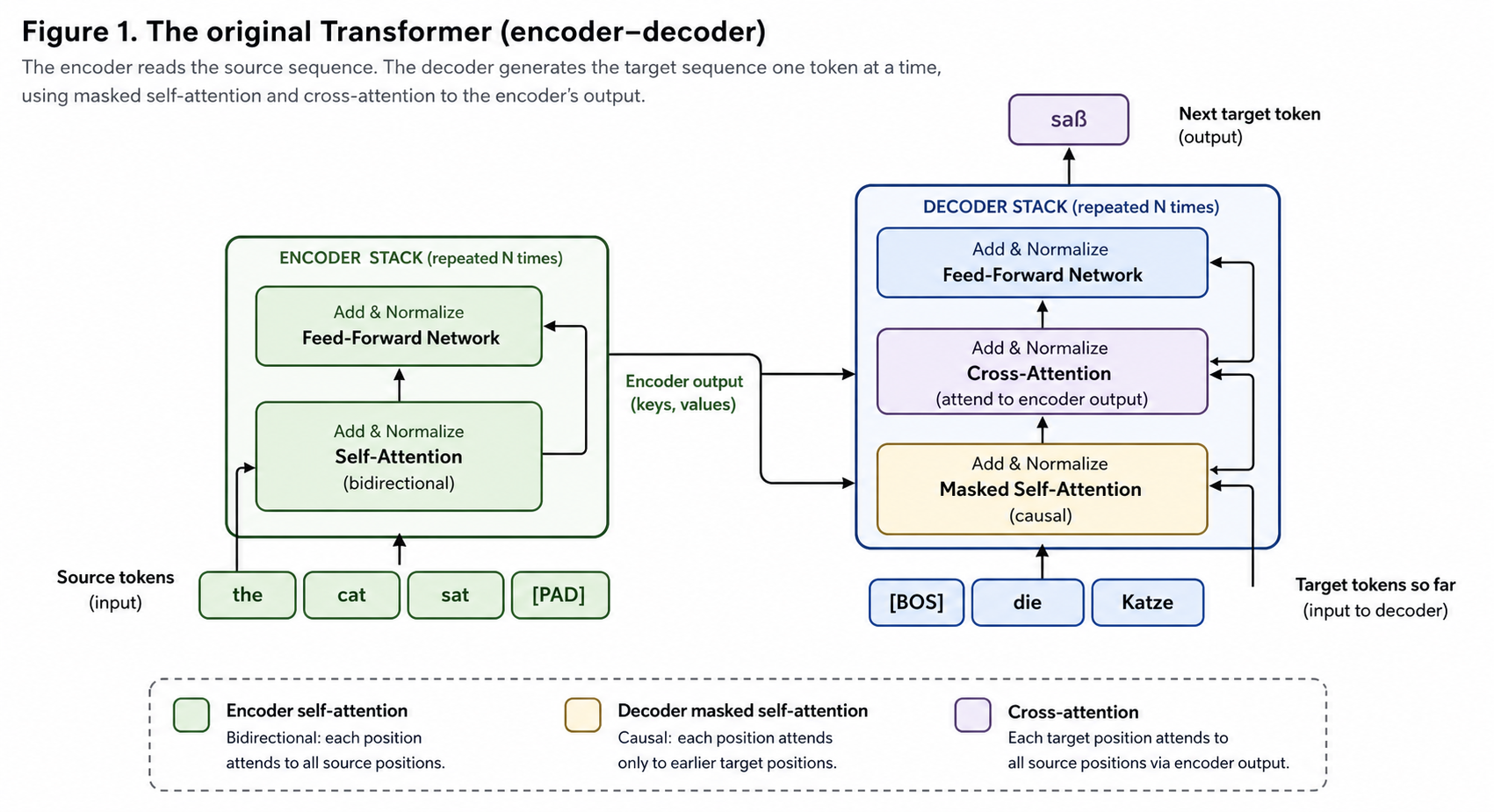
The left stack is exactly the encoder-only architecture from §1: bidirectional self-attention over the source sentence. The right stack is almost the decoder-only architecture from §2: causal-masked self-attention over the target sentence so far. The new piece is the cross-attention layer inside each block of the right stack, which lets each target position attend to every source position by reading keys and values from the encoder’s final output. In the original paper, both stacks have blocks.
This is also where the naming finally clicks. That cross-attention layer — the bridge from the right stack to the left — is what made the original decoder a decoder. The “decoder-only” models from §2 do not have it; with no encoder, there is nothing to cross-attend to. A more honest name would be “causal-masked Transformer,” but “decoder-only” stuck because these models, like the original decoder, generate autoregressively — emitting tokens left to right, conditioning each on what has already been produced.
4. Side by side
| Architecture | Self-attention | Cross-attention | Examples | Best for |
|---|---|---|---|---|
| Encoder-only | Bidirectional | None | BERT, RoBERTa, ModernBERT | Understanding |
| Decoder-only | Causal-masked | None | GPT, Llama, Claude | Open-ended generation |
| Encoder–decoder | Both kinds | Yes | T5, BART, original Transformer | Sequence-to-sequence |
The choice is task-driven. Need a representation? Encoder-only. Need to generate text from scratch? Decoder-only. Need to generate text conditioned on a different sequence (translation, summarization, structured generation from long input)? Encoder–decoder.
A practical note: encoder–decoder models like T5 (Raffel et al., 2019) and BART are still actively used for sequence-to-sequence tasks where the input and output are clearly distinct. But the gravitational center of the field has shifted to decoder-only, because anything you can frame as “continue this text” — which turns out to be a lot — can be done by a decoder-only model with the right prompt.
Summary
Self-attention is the mechanism. The three Transformer families are different ways to stack it.
- Encoder-only uses bidirectional self-attention. Everything sees everything.
- Decoder-only adds a causal mask. The future is hidden.
- Encoder–decoder adds a second stack and a cross-attention bridge between them.
In all three, the underlying attention layer is the same scaled-dot-product self-attention from the kernel regression derivation. The architectural differences are entirely about which positions can see which — controlled by masks and by which sequence each query reads from.
Built on the notation in From Kernel Regression to Self-Attention and Masks and Cross-Attention. Original architecture: Vaswani et al., “Attention Is All You Need”, NeurIPS 2017. BERT: Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, 2018. T5: Raffel et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”, 2019.