From Kernel Regression to Self-Attention: A Line-by-Line Derivation
·Reading time: 9 min
I have a mathematics background, and kernel regression is something I have studied deeply as part of advanced statistics.
Self-attention, on the other hand, felt slippery to me when I started learning it. It is confusing that the input tokens x play so many roles at once: they are queries, keys, and values.
If you happen to have the same background — comfortable with kernel regression, uncertain about attention — this post is for you. Following §15.4.2 and §15.5 of Kevin P. Murphy’s Probabilistic Machine Learning: An Introduction, I will derive self-attention from kernel regression step by step. I keep Murphy’s notation where possible so the post can be read alongside the book.
Suppose we have n training pairs (x1,y1),…,(xn,yn) with xi∈Rd and yi∈R, and we want to predict y at a new test point x. The Nadaraya–Watson estimator says: take a weighted average of the training labels, where the weight given to yi depends on how similar x is to xi:
f(x)=i=1∑nαi(x,x1:n)yi(1)
Here αi(x,x1:n)≥0 are weights that sum to one (for any fixed x). A standard way to build them is to start from a density kernel. We will use the Gaussian:
Kσ(u)=2πσ21exp(−2σ2u2)(2)
where σ is called the bandwidth. We build the weights αi by normalizing the kernel across training points. Because of the normalization, the prefactor 1/2πσ2 is irrelevant and we drop it:
Comparing (3) with (4), the weights are exactly a softmax — applied to the exponent of the Gaussian, not to its value. We give that exponent a name. Define the attention score
This is still pure kernel regression — we have only rewritten it. Now observe that the Gaussian score in (5) plays one specific role here: it measures how similar x is to each xi. Nothing in the structure of (7) forces that particular choice. Letting a(x,xi) refer to a generic similarity score — not just the Gaussian one — gives
f(x)=i=1∑nsoftmaxi(a(x,x1),…,a(x,xn))yi(8)
Equations (7) and (8) look identical — and that is the point. Only the meaning of a has widened: in (7) it is fixed to the Gaussian form (5); in (8) it is any real-valued function. No modelling power has been added; the similarity function has become a pluggable component. That small abstraction is what opens the door to the attention vocabulary.
so adding an i-independent constant to every score leaves the weights unchanged. The −∥q∥2/(2σ2) term is exactly such a constant and drops out. If we additionally assume keys are unit-norm, the third term −∥ki∥2/(2σ2) is also constant and drops out. What remains is a softmax-equivalent score — call it a~:
a~(q,ki)=σ2q⊤ki(12)
Because softmaxi(a(q,ki))=softmaxi(a~(q,ki)) for all i, we can replace a with a~ in (9) without changing any attention weight. This is the dot-product attention score. The bandwidth σ is still a free parameter; §5 determines its standard value.
In practice σ2=d, where d is the dimension of the query and key vectors, so the score (12) becomes a~(q,ki)=q⊤ki/d. The reason is statistical. Suppose the components of q and ki are independent, with mean zero and unit variance. Each product term qℓki,ℓ is then also mean-zero, with
Var(qℓki,ℓ)=E[qℓ2]E[ki,ℓ2]=1
Independence across ℓ means the variance of the sum is the sum of variances:
So the raw dot product has standard deviation d — it grows with dimension. Without rescaling, large-magnitude inputs push the softmax into a saturated regime where one score dominates and gradients with respect to the others vanish. Setting σ2=d keeps the score variance at O(1) independent of d, keeping the softmax in a well-behaved regime.
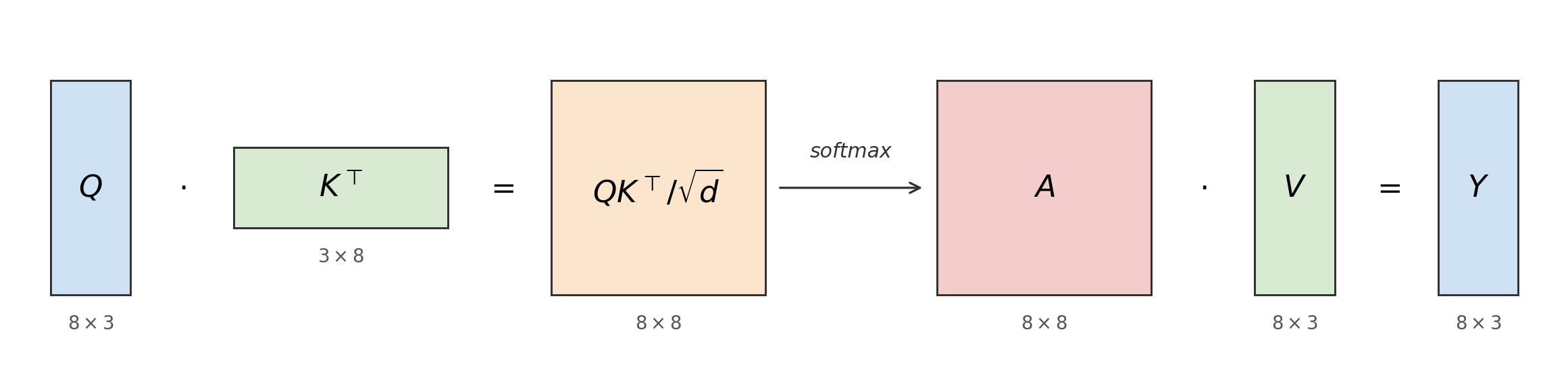
We now have all three ingredients: a softmax (6), a dot-product score a~ (12), and a 1/d rescaling. The whole pipeline vectorizes cleanly: stack the n queries, keys, and values as rows of matrices:
Q=q1⊤⋮qn⊤,K=k1⊤⋮kn⊤,V=v1⊤⋮vn⊤∈Rn×d
Then QK⊤ is an n×n matrix whose (i,j) entry is exactly the dot-product score a~(qi,kj)=qi⊤kj. To see this concretely, consider n=3 tokens and d=2:
Row i holds all the scores that query i assigns to every key. Scaling by 1/d and applying softmax row-wise turns each row into a probability distribution — the attention weights for that query. Multiplying by V then takes a weighted average of the value rows for each query, giving the output matrix Y∈Rn×d. This is exactly (9) computed for all queries at once:
Y=Attn(Q,K,V)=softmax(dQK⊤)V(13)
This is scaled dot-product attention — the exact formula from “Attention Is All You Need” [Vaswani et al., 2017]. Read left to right, the pipeline has a clear shape:
The i-th row of Y is the output for query i: a context-weighted blend of all the values, where the weights are determined by how well query i matches each key.
So far we have been in the kernel-regression setting: each training point came with a scalar label yi, and the value in (9) was vi=yi. A Transformer processes something different — a sequence of tokens x1,…,xn with no labels attached. There are no yi‘s. Every position has to supply its own payload.
The natural move is to let each token play all three roles. In self-attention, every position attends to every other position in the same sequence, using the tokens themselves for queries, keys, and values:
yi=Attn(xi,{(xj,xj)}j=1n)(14)
Each token xi acts simultaneously as a query (asking “who is relevant to me?”) and contributes a key and value (answering “here is what I offer to others”). This lets the model build context-dependent representations: the embedding of the word it can depend on whether the surrounding sentence is about an animal or a street. And because there are no recurrences, all n outputs y1,…,yn can be computed in parallel — this is what makes Transformers so much faster to train than RNNs.
To let keys and values carry different information — and more broadly, to let the model learn what aspects of each token to match on and return — introduce three learned linear projections:
q=W(q)x,k=W(k)x,v=W(v)x(15)
Each input x is passed through three different matrices before entering the attention formula. The matrices W(q),W(k),W(v) are learned end-to-end by backpropagation. Plugging (15) into (14) gives the full self-attention layer used in Transformers:
yi=Attn(W(q)xi,{(W(k)xj,W(v)xj)}j=1n)(16)
This is the step that turns nonparametric kernel regression into a trained attention mechanism. The key/value split from §3 now earns its keep: because W(k) and W(v) are independent matrices, a token can be matched on one aspect of itself and return another.
Gaussian kernelgeneralize similarity, renameexpand, drop constants, set σ2=dsequence attends to itselflearned projectionskernel regressionf(x)=i∑αi(x,x1:n)yinonparametric attentioni∑softmaxi(−2σ2∥x−xi∥2)yigeneral attentioni∑softmaxi(a(q,ki))viscaled dot-productsoftmax(dQK⊤)Vself-attention (keys = values)yi=Attn(xi,{(xj,xj)}j)Transformer self-attentionyi=Attn(W(q)xi,{(W(k)xj,W(v)xj)}j)
Self-attention is not a mysterious black box. It is the natural result of applying a Gaussian similarity kernel, normalizing with softmax, generalizing the similarity, letting a sequence attend to itself, and adding learned projections to rescue the key/value distinction. Every piece has a reason.
Primary reference: Kevin P. Murphy, “Probabilistic Machine Learning: An Introduction”, MIT Press (2022). The kernel-regression-as-attention framing is developed in §15.4.2 (pp. 520–521); self-attention and the transformer architecture are covered in §15.5–15.5.2 (pp. 526–527). Available online at probml.github.io/pml-book/book1.html. Original transformer paper: Vaswani et al., “Attention Is All You Need”, NeurIPS 2017.
AI Chat
Messages you send are processed by the Google Gemini API to generate responses. Do not share sensitive personal data. See the privacy policy for details.