Masks and Cross-Attention: Extending Self-Attention
This post is a follow-up to From Kernel Regression to Self-Attention — same notation, same setup. There we ended with full self-attention, where every position in a sequence attends to every other position using learned projections of itself. That is the mechanism. In practice, two extensions are layered on top before you get to a real Transformer:
- Masks, which restrict which positions a query is allowed to read from. The most important is the causal mask used in autoregressive language modeling, but padding masks come up routinely in batched training.
- Cross-attention, which relaxes the self part: queries come from one sequence, keys and values from another. This is what lets one sequence be conditioned on another.
Both are small modifications to equation (13) of the previous post. The mechanism — scaled dot product, softmax, weighted average — is unchanged in both cases. What changes is which positions are allowed to attend to which, and which sequence each input comes from. This post covers both.
1. The leakage problem
A decoder-only language model is trained on next-token prediction: given tokens , it should predict from the output at position , for every .
At inference time, this constraint is automatic — when generating token , only tokens exist. There is nothing to leak. At training time, the situation is different. The point of a Transformer is parallelism: we want to compute in a single forward pass, with all targets visible. But equation (16) from the previous post says
Position attends to all positions , including those with . The model can read the future and copy it into . Loss goes to zero; nothing has been learned.
We need a way to keep the parallelism but block any flow from positions to position .
2. The fix: before softmax
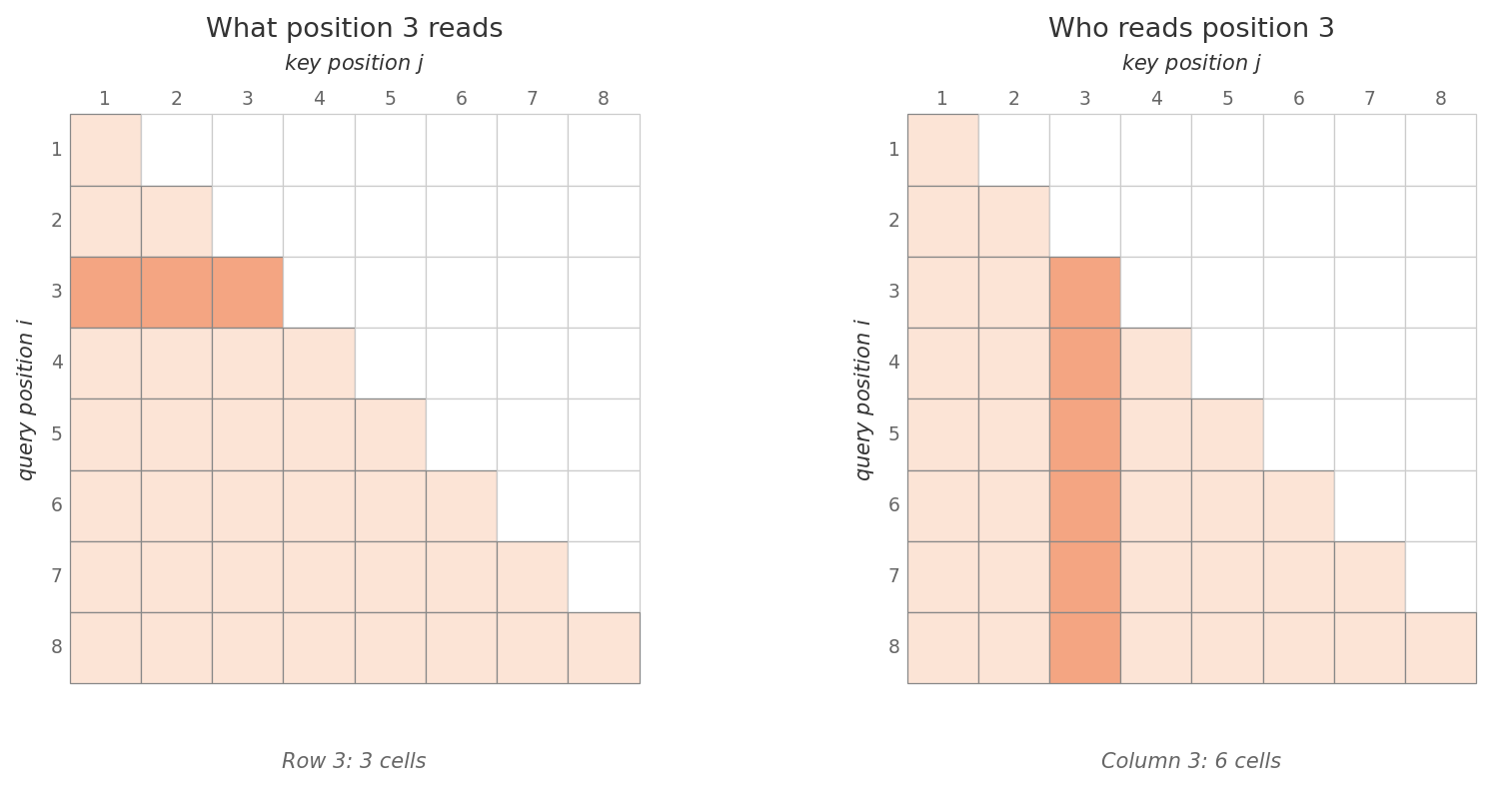
The mechanism is small. In the score for query against key , replace with whenever . After softmax, , so those positions receive exactly zero attention weight. The remaining weights — over keys — renormalize to sum to one.
Concretely, this is achieved by adding a mask matrix to the score matrix before softmax:
Equation (13) from the previous post becomes
The softmax is applied row-wise. After masking, the attention matrix is lower-triangular: row has nonzero entries only in columns .
In code, is typically a large negative constant like , which is numerically equivalent for floating-point softmax.
3. What changes, what doesn’t
The mechanism is unchanged. Queries still come from , keys from , values from ; the dot-product score and the rescaling are exactly as in §5 of the previous post. All that has changed is which scores survive the softmax.
The asymmetry is worth dwelling on. Position no longer sees positions , but position (with ) still sees position . The mask makes information flow strictly forward through the sequence. Each output is now a weighted average over only its own past — exactly the constraint autoregressive training requires.
Parallelism is preserved. All outputs are still computed in a single matrix multiplication, just with a triangular attention pattern instead of a full one. This is what lets decoder-only Transformers train at the same speed as bidirectional ones, despite the stricter information constraint.
4. Padding masks
A second, more mundane use of masking comes from batching. Real training batches contain sequences of different lengths. To pack them into a single tensor, shorter sequences are padded with a special token up to the length of the longest. These padding tokens carry no meaning and should not contribute to any output.
The same trick handles them. Build a padding mask where whenever key is a padding token, and otherwise. Add it to the scores before softmax. In a decoder, both masks combine: , which is still wherever either is.
5. Cross-attention
The second extension is cross-attention. In self-attention, the query, key, and value all come from the same sequence — that is what makes it self. Cross-attention relaxes this: queries come from one sequence, keys and values from another.
Concretely, given two sequences — call them with rows and with rows — cross-attention lets every position in attend to every position in . The learned projections from §8 of the previous post split as follows:
Three things are worth noting:
- The mechanism is unchanged. Scaled dot product, softmax, weighted average — exactly equation (13). Only the inputs differ.
- The score matrix changes shape. Stacking ( rows) and ( rows), the score matrix is instead of the we have seen so far. Each row holds the scores from query position in against every key position in .
- Self-attention is the special case where . When the two sequences are identical, queries, keys, and values all come from the same source, and we are back to (13) plus the learned projections.
In matrix form:
— one output vector per position in , where each output is a weighted blend of the value rows derived from . Most of the previous post carries through unchanged; the only difference is the interpretation of where each input comes from.
The most prominent use is in encoder–decoder Transformers, where decoder positions attend to the encoder’s output — that is what lets a translation model align “die Katze saß” with “the cat sat.” But the mechanism is general: it shows up wherever a model needs to condition one sequence on another.
Summary
Self-attention as derived in the previous post lets every position attend to every other position in the same sequence. Two extensions cover most of what real Transformers do:
- Masking sets entries of the score matrix to before softmax, blocking flow from masked positions. Causal masks block the future; padding masks block padding tokens. Both rely on .
- Cross-attention lets queries come from one sequence and keys/values from another. The mechanism is otherwise identical; only the score matrix changes shape from to .
A single formula subsumes all three cases — vanilla self-attention, masked self-attention, and cross-attention:
When , , come from the same sequence and , this is the original (13). When encodes a causal or padding mask, this is masked self-attention. When comes from one sequence and , from another, this is cross-attention. The next post shows how Transformers stack these into encoder-only, decoder-only, and encoder–decoder architectures.
Built on the notation and derivation in From Kernel Regression to Self-Attention. Causal masking and cross-attention both originate with Vaswani et al., “Attention Is All You Need”, NeurIPS 2017, §3.2.