Orchestrating ML Data Pipelines with Snakemake: A Real-World Case Study
When you’re handed thousands of customer support tickets and asked to analyse them—classify intents, prepare training data, and keep the pipeline reproducible—you quickly run into a familiar problem: expensive computational steps (LLM calls, PII censoring) that don’t scale if run naively. I tackled this on a real project by orchestrating the entire pipeline with Snakemake. This post summarises what the pipeline did and three ways Snakemake made it manageable and efficient.
The Challenge
I had over 2000 tickets exported from Zendesk. The goal was to classify each ticket by customer intent (e.g. billing questions, technical issues, feedback) so we could later build a first-level customer support AI agent. The classification was iterative: define intents, run an LLM over the tickets, inspect how many remained unclassified or misclassified, then refine the intent taxonomy and repeat. Doing this without a proper workflow would have meant manual scripts, ad-hoc reruns, and a lot of duplicated work.
Pipeline Overview
The Snakemake pipeline has 19+ stages. At a high level it:
- Ingests raw ticket data (filter by segment, subsample if needed).
- Cleans and normalises tickets (flag conversation-style tickets, fix malformed records, extract a consistent set of fields).
- Censors sensitive data so downstream steps and training data never see PII.
- Classifies comment authors (customer vs agent vs unknown) using an LLM where metadata was missing.
- Labels tickets by intent with an LLM, using the same chunk structure for efficiency.
- Produces two outputs: a censored dataset for training, and an uncensored (in-memory/view-only) path for inspection in a Streamlit app.
- Prepares training data: filter to labeled tickets, drop non-actionable intents, balanced subsample per intent, truncate agent resolution, and transform into the final training format.
The pipeline maintains two parallel paths: a censored dataset for training (ensuring PII never reaches the LLM or training data) and an uncensored view for internal debugging in a Streamlit app.
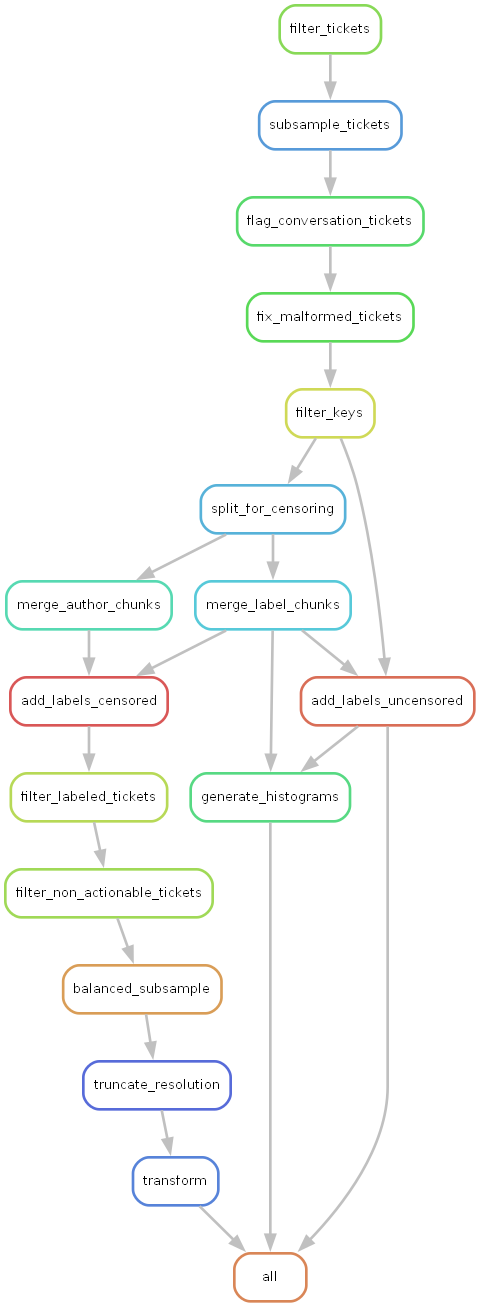
The rule graph below gives a bird’s-eye view of the workflow and its dependencies.
What the Data Looked Like (Without the Data)
Tickets were Zendesk-style exports. Each ticket had:
- Identifiers and metadata: ticket ID, channel (e.g. email, chat), satisfaction score when available.
- Comments: a time-ordered list of entries, each with timestamp, body text, and an author role (customer, agent, or sometimes unknown when the export didn’t carry that information).
The pipeline first reduced each ticket to a fixed set of fields (IDs, channel, satisfaction, comment list with normalised author and body). Sensitive content in comment bodies was then censored (e.g. names, emails) so that all downstream steps—including LLM labelling—operated on safe, anonymised text. Below is one example ticket with intent ReceiveTickets, with all identifying details replaced by dummy data and uninteresting fields omitted, to illustrate the structure:
{
"id": 10001,
"subject": "Tickets wurde nicht geschickt",
"channel": "email",
"comments": [
{
"body": "Sehr geehrte Damen und Herren,\n\nich habe online 2 Tickets gekauft\nSent from my iPhone",
"created_at": "2025-11-05T10:01:57Z",
"author_role": "customer"
},
{
"body": "Guten Tag,\n\nich habe Ihnen die Kaufbestätigung nochmals zugesandt.\nZur Sicherheit hänge ich die Tickets an diese Mail mit an.\n\nMit freundlichen Grüßen\nSupport-Team",
"created_at": "2025-11-05T10:14:46Z",
"author_role": "agent"
}
],
"customer_intent": "ReceiveTickets"
}The important point is that this structure (one record per ticket, list of comments with roles and text) drove how we split work into chunks and merged it back.
Three Ways Snakemake Helped
1. Scatter–Gather for Expensive Steps
The heaviest steps were: PII censoring, LLM-based author classification, and LLM-based intent labelling. Running them over 2000+ tickets in one go would have been slow and brittle. So we used a scatter–gather pattern. The censoring step uses Microsoft Presidio with multilingual NLP models (English and German) to detect PII, then replaces it with realistic synthetic data via Faker, maintaining consistency within each ticket.
- Scatter: A checkpoint rule splits the extracted tickets into chunks (e.g. 500 tickets per chunk) and writes a manifest of chunk filenames.
- Process in parallel: Each chunk is processed by its own rule (e.g.
censor_chunk,classify_authors_chunk,label_llm_chunk). Snakemake can run these in parallel with--cores N. - Gather: A merge rule collects all chunk outputs into a single file (e.g. censored tickets, author-labelled tickets, or per-model label CSVs).
Example: the censoring stage is implemented as a checkpoint split, a parameterised chunk rule, and a merge that uses a function to discover chunk names from the manifest:
checkpoint split_for_censoring:
input:
input_path = "data/tickets/06_extracted/tickets.jsonl"
output:
manifest = "data/tickets/07_chunks_uncensored/manifest.txt"
params:
output_dir = "data/tickets/07_chunks_uncensored",
chunk_size = config.get("parameters", {}).get("chunk_size", 500)
shell:
"uv run src/processing/split_tickets.py {input.input_path} {params.output_dir} --chunk-size {params.chunk_size}"rule censor_chunk:
input:
chunk = "data/tickets/07_chunks_uncensored/chunk_{i}.jsonl",
config = "config.yaml"
output:
censored = "data/tickets/08_chunks_censored/chunk_{i}.jsonl"
shell:
"uv run src/processing/censor_sensitive_data.py {input.chunk} {output.censored} --config {input.config}"rule merge_censored_chunks:
input:
chunks = get_censored_chunks
output:
output_path = "data/tickets/09_censored/tickets.jsonl"
params:
input_dir = "data/tickets/08_chunks_censored"
shell:
"uv run src/processing/merge_tickets.py {params.input_dir} {output.output_path}"get_censored_chunks reads the manifest produced by the checkpoint and returns the list of censored chunk paths, so the merge rule stays correct even when the number of chunks changes. The same pattern is reused for author classification and for LLM labelling (with labels stored per model so we could experiment with different models). Scatter–gather was the main lever to parallelise expensive work and bring wall-clock time down.
2. Incremental Processing with Checkpoints
Because we refined customer intents iteratively, we often re-ran the pipeline after changing only the intent definitions or a few scripts. Without checkpoints, we would have had to re-run every step after the split. With a checkpoint that produces the manifest, Snakemake knows the set of chunks only after the split runs. Downstream rules (merge, or any step that depends on “all chunks”) are then scheduled after the checkpoint, and only chunks whose inputs changed get re-executed. That meant we could re-run after intent tweaks and only recompute the chunks that were actually affected, saving a lot of time during the iterative refinement phase.
3. Dependency Management and Reproducibility
With 19+ steps, two output paths (censored for training, uncensored for viewing), and several scatter–gather phases, hand-managing the order of operations would have been error-prone. Snakemake’s DAG took care of it: we just declared inputs and outputs for each rule, and the correct execution order and parallelisation followed. That gave:
- Reproducibility: Same inputs and config produce the same outputs; the pipeline is fully specified in the Snakefile and config.
- Maintainability: Adding or changing a step (e.g. a new filter or transformation) is a matter of adding or editing a rule and wiring inputs/outputs.
- Transparency: The rule graph (as in the figure above) makes the whole pipeline visible at a glance, which helps both debugging and onboarding.
The pipeline is also model-agnostic: labels are stored per-model (e.g. data/tickets/13_labeled/Qwen_Qwen3-Coder-480B/), allowing easy experimentation with different LLMs without reprocessing tickets.
Outcome
The pipeline successfully processed and classified the full ticket set into 20+ distinct customer intent categories (e.g. ReceiveTickets, CancelReservation, RefundRequest), supported iterative refinement of the customer intent taxonomy, and produced the datasets needed to train a first-level customer support AI agent (in a separate repo). Snakemake’s scatter–gather pattern, checkpoints, and DAG-based orchestration were central to keeping the workflow efficient and maintainable—exactly the kind of structure that scales to larger datasets and more complex MLOps pipelines.
If you’re designing data or ML pipelines with expensive steps and iterative development, Snakemake is a strong candidate: you get parallelisation, incremental runs, and a clear, declarative specification of the whole workflow in one place.