Deep Learning-Based Diabetic Retinopathy Detection in Fundus Images
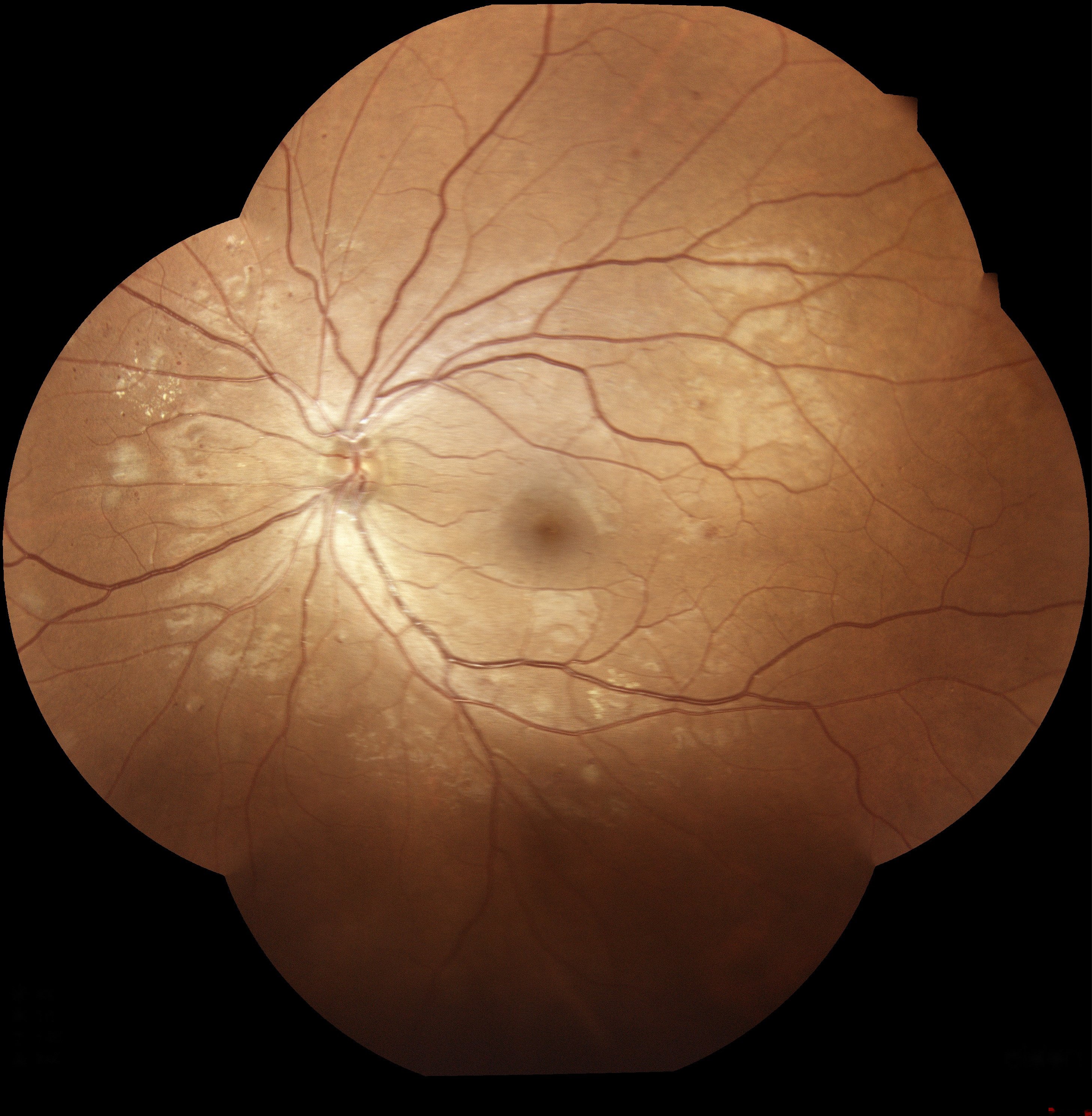
This blog post is based on a group project completed in the “Deep Learning” class at Yale University under the guidance of Professor Smita Krishnaswamy. The project was a collaborative effort with Alaa Alashi, Taieb Bennani, and Xinyue Qie.
Diabetic retinopathy (DR) is a prevalent retinal disorder affecting over 103 million individuals with diabetes globally, with numbers predicted to rise to 125 million by 2030. Timely diagnosis is vital as untreated DR can lead to serious consequences, including irreversible retinal detachment, neovascular glaucoma, diabetic macular edema (DME), and potential vision loss. Fundus photographs displaying hemorrhages and exudates are used by medical professionals to diagnose DR, and precise classification algorithms can enhance diagnostic efficiency and accuracy, enabling earlier intervention and management.
The potential benefits of artificial intelligence (AI) in DR diagnosis are particularly significant in developing countries, where the doctor-to-population ratio is lower than in developed nations. In this project, we developed a two-pronged deep learning approach for DR detection using high-resolution fundus images from a specialized rural ophthalmic clinic in Morocco. Our method combines binary classification to identify DR presence and image segmentation to quantify hemorrhages and exudates—two critical indicators of disease severity.
Dataset and Clinical Context
Our model was trained on a novel dataset comprising 126 high-resolution, de-identified fundus images obtained from a private clinic in Morocco. The dataset consists of 95 images labeled as DR and 31 labeled as non-DR, reflecting the clinical reality of a specialized ophthalmic surgery clinic where patients with existing DR are more prevalent. To ensure standardization, all images were obtained using the same screening technology.
Images are de-identified and used for educational purposes with appropriate permissions.
The retina plays a crucial role in vision, as it receives light and converts it into neural signals sent to the brain. DR develops when sustained high blood sugar levels cause damage to the small capillaries supplying the retina. These damaged blood vessels may leak blood and fluid, leading to the formation of hemorrhages and exudates. Hemorrhages result from blood leakage and appear as small dark red or maroon spots in fundus images, while exudates appear as yellowish-white deposits resulting from the accumulation of lipids and proteins. These features are clinically meaningful as they provide vital information about disease severity and progression.
To optimize model performance, we implemented preprocessing steps including removal of screening equipment parameters from image corners and resizing all images to uniform dimensions (default 256×256 pixels, with hyperparameter variations).
Binary Classification with ResNet
Problem Formulation
Let represent our preprocessed input fundus images, and let denote the DR status for each sample, where if sample has DR and otherwise. We develop a binary classification algorithm aimed at accurately classifying whether a patient has DR from the input fundus images.
We build upon a pre-trained ResNet architecture with 50 layers from the torchvision library. ResNet is a specific kind of convolutional neural network known for its ability to facilitate the training of deep networks, thanks to the introduction of residual connections that address the vanishing gradient problem and improve performance.
Handling Class Imbalance
Due to the nature of the clinic where non-DR images were obtained, our dataset had significantly fewer non-DR images (31 vs. 95 DR images). As class imbalance can negatively impact classification algorithms, we implemented two strategies to address this issue.
Approach 1: Oversampling We oversampled the non-DR images in the training dataset with replacement to create a balanced training dataset with equal numbers of DR and non-DR images.
Approach 2: Weighted Cross-Entropy Loss We applied a weighted cross-entropy loss function to penalize false classification of non-DR images. The standard cross-entropy loss is:
For the weighted version, we assign different weights to misclassified non-DR images compared to misclassified DR images. With , our loss function becomes:
We experimented with to find the optimal balance.
Hyperparameter Tuning and Results
To optimize our model’s performance, we conducted a comprehensive grid search over hyperparameters including learning rate ( to ), batch size (8, 16), optimizer (SGD, Adam), momentum (0.9 for SGD), and balancing strategy (none, oversampling, weighted loss). We quantitatively measured performance using accuracy, precision, recall, and F1-score on training and testing sets.
The best results were obtained using a learning rate of , a batch size of , oversampling the underrepresented non-DR class in the training dataset, and the SGD optimizer. This configuration achieved:
- Testing precision: 0.967
- Testing recall: 0.935
- Testing accuracy: 0.921
Interestingly, almost all configurations produced high testing recall, with 10 out of 18 experiments achieving a testing recall above 0.9. The oversampling method achieved the highest testing precision, while the weighted cross-entropy improved testing recall. The SGD optimizer generally outperformed the Adam optimizer for the default hyperparameter configurations. Training converged after 35 epochs, indicating stable learning.
Image Segmentation with U-Net
Architecture and Motivation
In the project’s second phase, we focused on deeper analysis through image segmentation to quantify the presence of hemorrhages and exudates. Accurate quantification enables assessment of retinopathy degree, facilitating determination of appropriate treatment and surgical procedures.
The U-Net architecture is a popular convolutional neural network designed specifically for semantic segmentation tasks. Its encoder-decoder structure excels at identifying important details in input images and creating accurate segmentation masks. The architecture consists of:
- Encoder: A series of convolutional blocks, each followed by a max-pooling layer, systematically reducing spatial dimensions while increasing depth to learn hierarchical features
- Bottleneck: A convolutional block connecting encoder and decoder, enabling learning of abstract high-level features
- Decoder: Reconstructs the segmentation mask by progressively upscaling feature maps using up-sampling layers, combining up-sampled features with corresponding encoder features via skip connections (concatenation)
- Output layer: Employs softmax activation to produce per-pixel class probabilities, resulting in a segmentation mask where each pixel is assigned to one of the classes (exudates, hemorrhages, or background)
We added L2 regularization to prevent overfitting.
Data Labeling and Processing
We utilized the VGG Image Annotator software to label DR images accurately, creating a custom region attribute called “Abnormality” with a dropdown menu to differentiate between hemorrhages and exudates. With the assistance of a retinal specialist, we labeled 76 DR images. We used rectangles to label the images, though polygons would have been more accurate given the oval shapes of hemorrhages and exudates.
After labeling, we exported a CSV file containing positions of each hemorrhage and exudate, including x and y coordinates and height and width of rectangles. We created ground truth masks with two channels—one for hemorrhages and one for exudates—serving as pixel-wise representations for training the U-Net model.
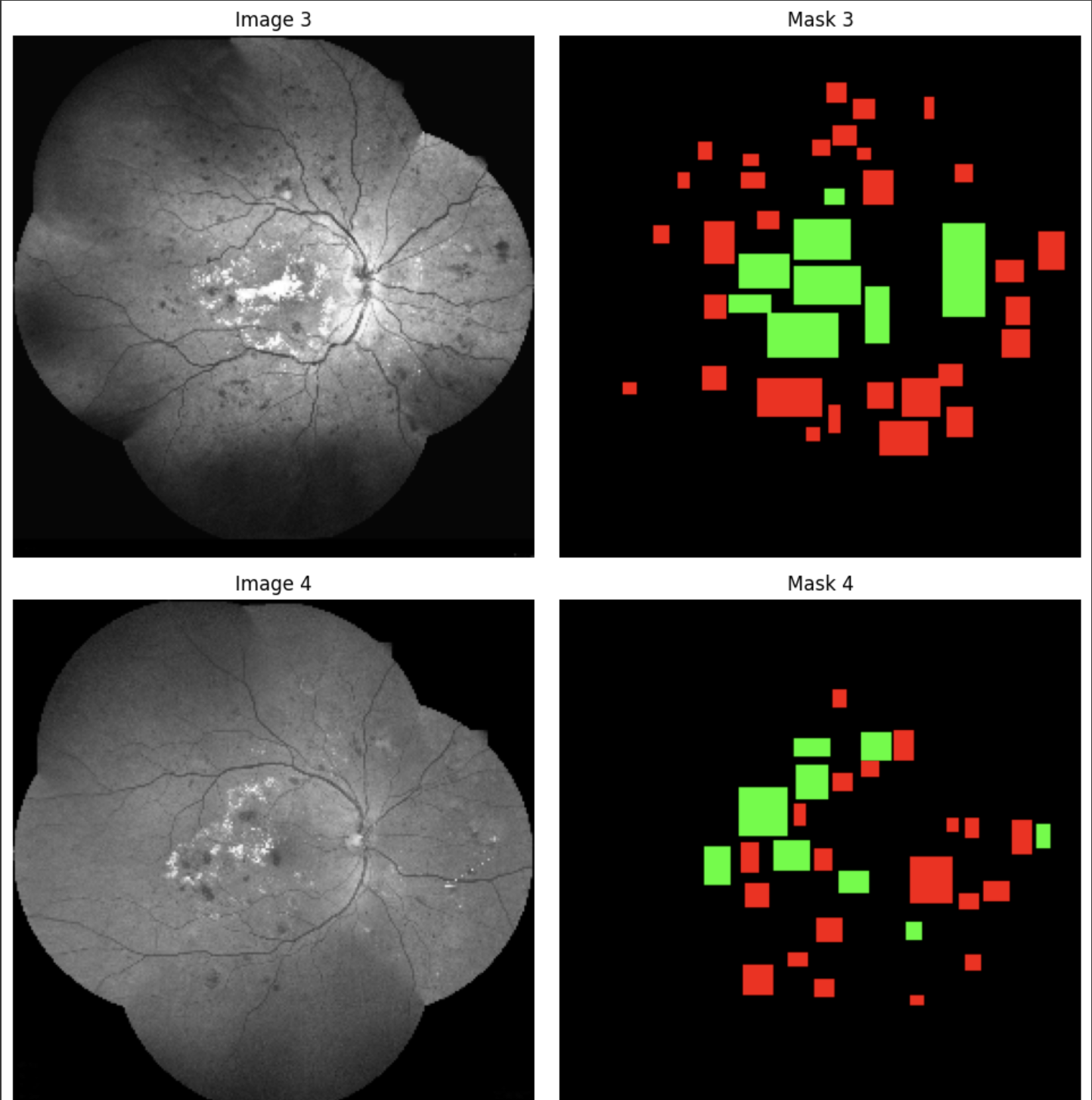
Data Augmentation
Given the limited dataset of 67 fundus images for segmentation, data augmentation was crucial to artificially expand the dataset and improve generalization. We used TensorFlow Keras ImageDataGenerator with the following augmentation parameters:
- rotation_range: Randomly rotate images up to 20 degrees
- width_shift_range and height_shift_range: Randomly shift images horizontally and vertically by 10% of their dimensions
- zoom_range: Randomly zoom in or out by up to 10%
- horizontal_flip and vertical_flip: Randomly flip images
- fill_mode: ‘nearest’ to fill empty pixels
Separate ImageDataGenerators were created for both images and their corresponding masks, synchronized with a common seed value to ensure augmentations applied to images match those applied to masks.
Hyperparameter Tuning and Results
We used the Keras Tuner library to search for optimal hyperparameter values during training. The search space included:
- Encoder filters: Ranges from [32, 128] to [128, 512] with step size 32
- Bottleneck filters: Range [256, 1024] with step size 64
- Decoder filters: Ranges from [128, 512] to [32, 128] with step size 32
- Learning rate: Floating-point values within [1e-4, 1e-2] sampled on a logarithmic scale
The model was trained with 50-100 epochs, batch size of 8, and a train/test/validation split of 70%/20%/10%.
We evaluated segmentation performance using key metrics:
-
Dice Coefficient: Measures similarity between predicted and ground truth segmentations, ranging from 0 (no overlap) to 1 (perfect match)
-
Mean Intersection over Union (IoU): Calculates the average ratio of intersection to union for each class
-
Accuracy: Proportion of correctly classified pixels
-
Recall: Proportion of correctly identified positive instances
Our segmentation model achieved:
- Accuracy: 0.9716
- Recall: 0.7220
- Jaccard Index (IoU): 0.4753
- Dice Coefficient: 0.6696
The high accuracy suggests many pixels were accurately classified, though the moderate recall and overlap metrics indicate potential for improvement. Notably, detection of hemorrhages was significantly more accurate than exudates, with recall and accuracy metrics close to 1 for hemorrhages. This discrepancy is clinically understandable: exudates can be challenging to identify even for specialists, as they can be mistaken for cotton wool spots (fluffy white patches resembling exudates) or camera artifacts.
Discussion and Future Directions
Our study highlights the potential of AI, particularly ResNet and U-Net models, in detecting and quantifying hemorrhages and exudates in fundus images for DR diagnosis and management. These findings could be particularly beneficial in developing countries with limited access to specialized ophthalmic care.
However, several limitations should be addressed in future work. The dataset’s small size (126 images for classification, 67 for segmentation) and class imbalance may have negatively affected model performance despite mitigation strategies. To improve classification accuracy, it would be beneficial to include more non-DR fundus images and expand the dataset to around a thousand images with better balance.
For segmentation, the rectangular labeling method, while practical, is not ideal for training U-Net models as it includes regions that are not hemorrhages or exudates. Future work should use polygons, ovals, or irregular shapes that better fit the edges of these abnormalities. Additionally, consulting professional ophthalmologists for precise identification and labeling of exudates would provide more accurate training labels.