Strategic Model Selection in Cursor: Balancing Cost and Performance
Checking Cursor’s pricing and a leaderboard back and forth is tedious; using “the best” model for everything can lead to surprisingly high bills. A simpler approach: one stronger model for planning, one cheaper model for execution.
The two-model strategy
Planning (understanding the task, designing steps) benefits from strong reasoning. You send context and get back a plan and a few key decisions; token volume is modest, so the extra cost is often worth it.
Execution (implementing the plan, writing code) can be done well by cheaper models when the plan is clear. This phase uses many more tokens, so keeping cost per token low matters.
- Use a premium model for planning: start the task, get a clear plan, maybe one or two critical edits.
- Switch to a cheaper model for execution: implement the rest, iterate, run tests.
You avoid both the “everything on the best model” bill and the “everything on the cheapest” quality hit.
Why it works
Planning is input-heavy (lots of context in, compact plan out); execution is output-heavy (lots of code generated). Arena Code benchmarks show that mid-tier models are close to the top on code tasks at a fraction of the cost. So: strong reasoning where it matters, lower cost where most tokens are spent.
Cost vs performance at a glance
The chart below plots cost (weighted $/1M tokens: 70% input, 30% output) vs benchmark performance. Data comes from Cursor’s pricing and public benchmarks; the workflow updates it daily.
Loading chart…
How to read it: Lower left = cheaper/weaker, upper right = pricier/stronger. Pick a planning model from the upper-right and an execution model from the lower half.
A caveat on token usage
The charts above and the recommendations below think in price per 1M tokens, but total cost for a task also depends on how many tokens each model uses for the same request. Some models are more verbose or expand the context more aggressively; others stay more compact.
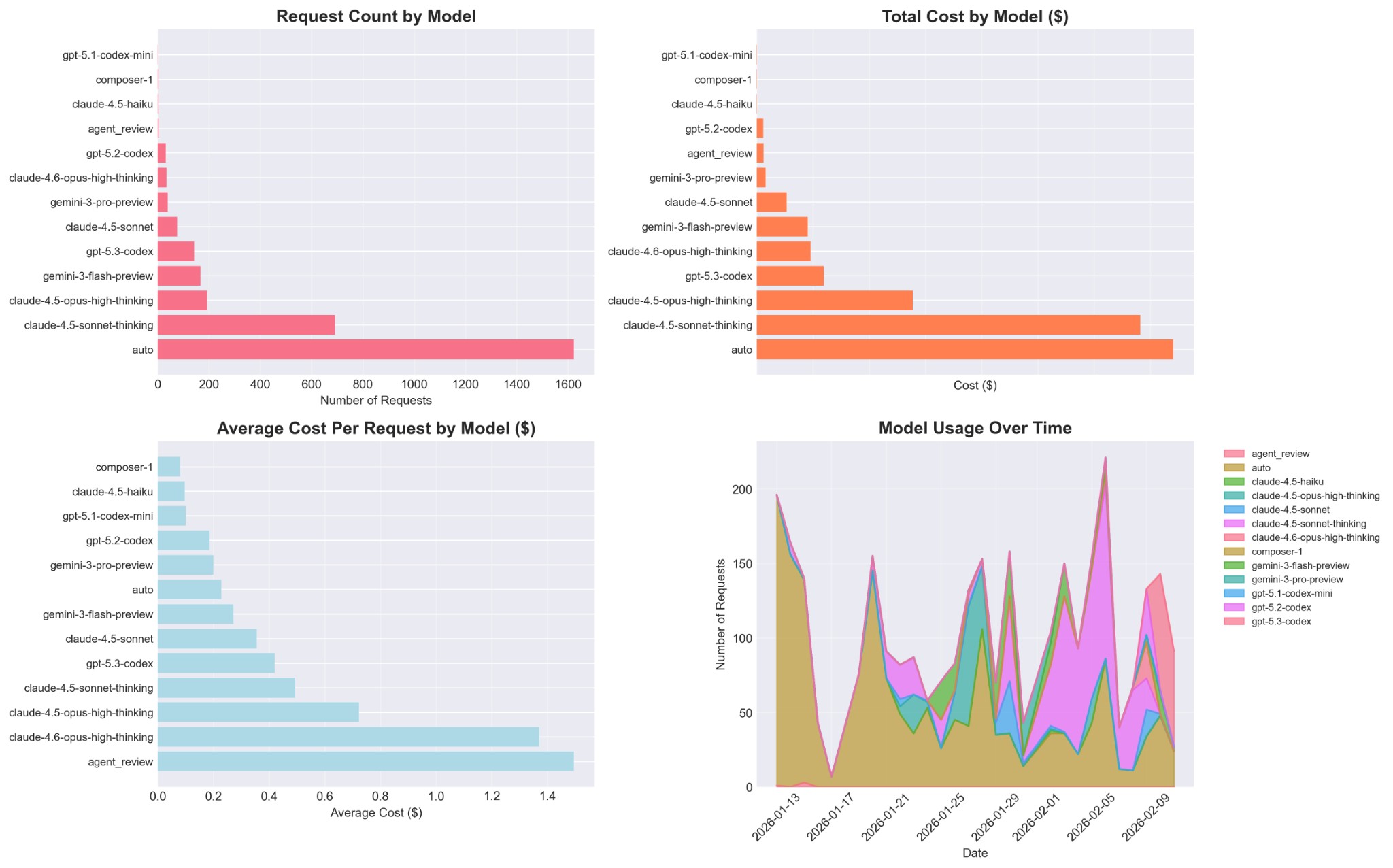
The figure above shows that request volume and spend are distributed very unevenly across models—“auto” and a few heavily used models dominate total cost even when their list price is modest.
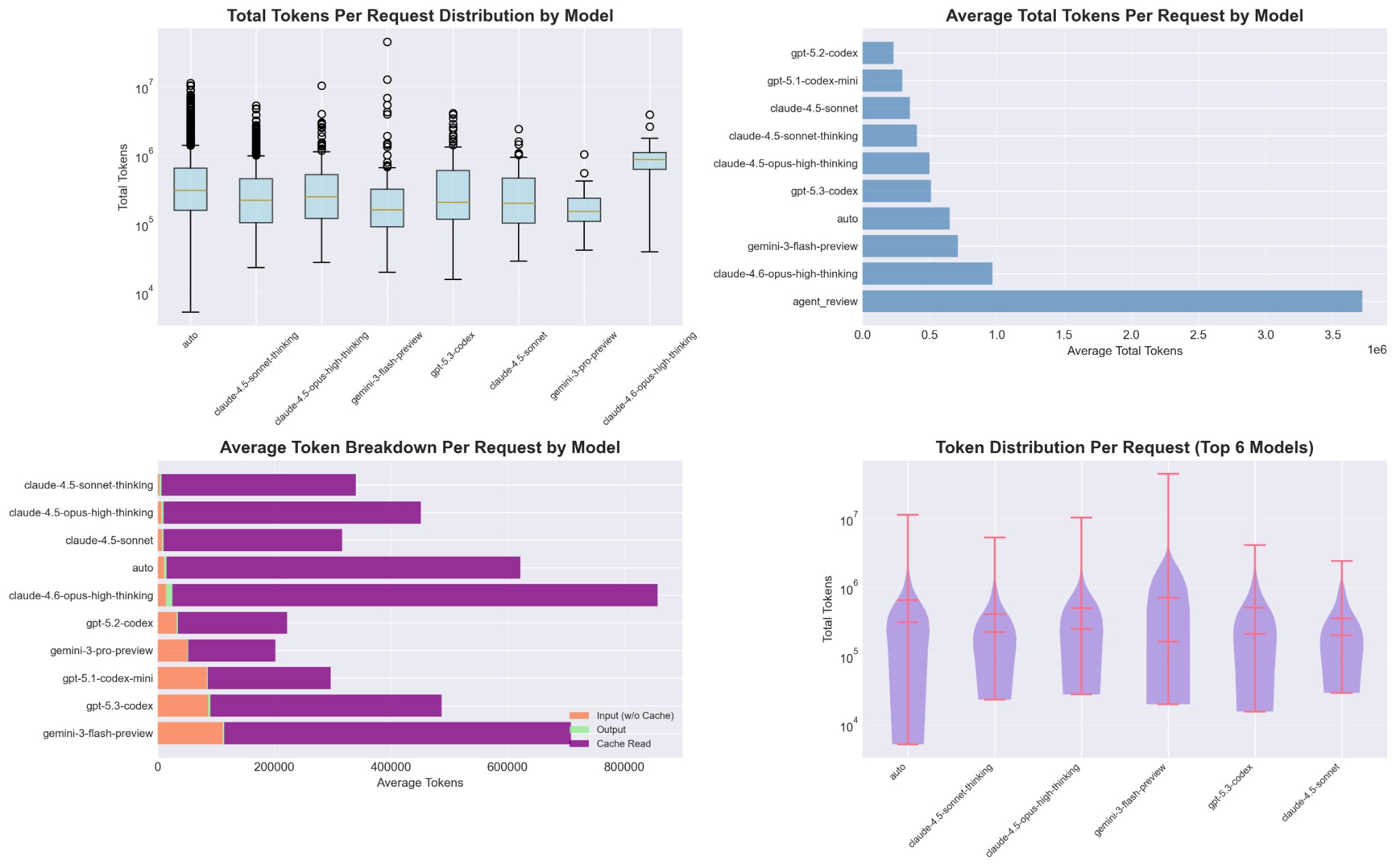
Here you can see that total tokens per request can differ by orders of magnitude between models for similar tasks. When you experiment with alternative models, keep an eye not just on price per token and Elo, but also on how long responses are and how much context they tend to pull in; that combination is what ultimately shows up on your bill.
Recommended pairings
How recommendations are selected
Recommendations follow a mathematical approach for optimal cost-performance trade-offs. The chart shows Pareto frontiers as dashed lines (purple for planning, green for execution).
Mathematical formulation:
Step 1: Minimum performance threshold
Only models with Arena-Code or LMSYS Arena Elo scores qualify (no BigCodeBench-only models).
Step 2: Category criteria (not mutually exclusive)
Step 3: Pareto optimality (no dominated models)
Within each category, keep only Pareto-optimal models. A model qualifies only if no other model is both better-performing and cheaper, ensuring you never choose a strictly dominated option:
Step 4: Rank by efficiency and select top picks
Models are ranked by Elo per dollar. Select 4 models by efficiency per category (or fewer if frontier is smaller).
This approach guarantees recommended models represent the best cost-performance trade-offs available. The formula runs daily via GitHub Actions.
Example workflow
- Start with the planning model. Describe the goal, attach files, ask for a step-by-step plan.
- Lock in the plan. Review, maybe one short follow-up, then switch model.
- Switch to the execution model. Refer to the plan and implement step by step; do most coding here.
- Use the planning model only when needed. For design decisions or subtle bugs, switch back briefly, then return to the cheaper model.
Takeaways
- Use one stronger model for planning and one cheaper model for execution instead of one model for everything.
- The chart is updated daily—use it to check cost vs performance without tab-hopping.
- Pick planning from the upper-right of the chart, execution from the lower half, and switch as you move from planning to coding.